最近再开展整合系统的工作,将原有系统中的共用逻辑抽离出来形成一个中台系统,根据业务开展形式的不同,划分出各个子系统。
在开展的过程中,遇到一种情况,在一些场景下子系统需要根据中台系统的一些操作去初始化自身的业务数据。
我们准备用事件( Event ) 的形式来解决这个问题,子系统监听中台系统发布的一些事件,当中台系统进行相关操作时,触发事件通知监听中的子系统。
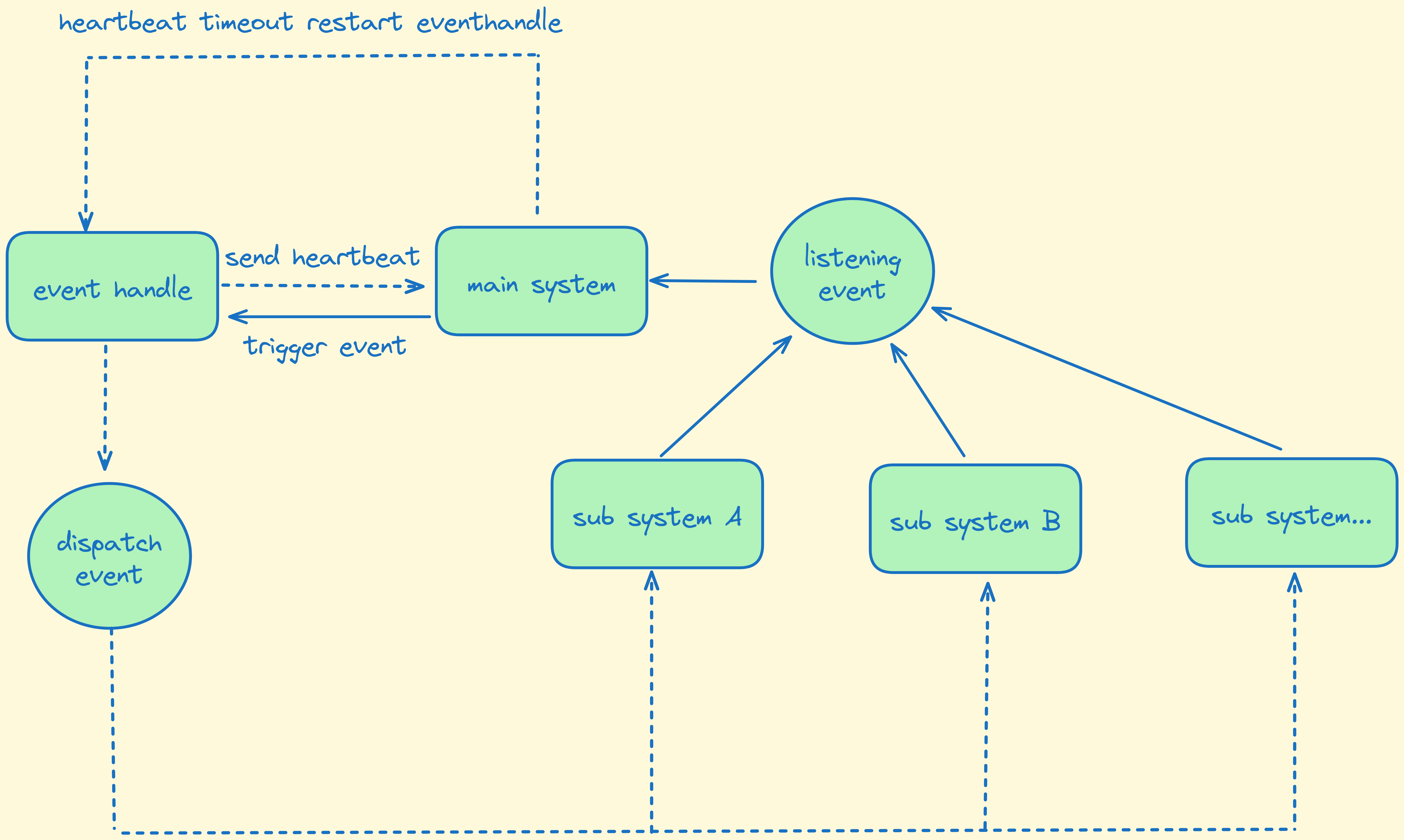
我们的中台系统 ( main system ) 是用 go 语言开发的,事件的触发是通过队列的形式发送给 event hadle 然后由它去发送事件通知到各个子系统。
在一些其他语言中,队列的消费一般都是启动一个进程来监听处理。而 go 有协程,可以用更轻量的协程来处理队列消费,这样以来有一个直接的好处就是服务启动了,队列的消费者就跟着启动了,不需要单独维护一个进程的启停。
当然要实现上述能力,有几个问题需要解决:
-
协程消费者如果崩溃了,不能影响主进程的运行
-
协程异常要能重新拉起一个新的消费者,保证协程消费者能一直运行。
崩溃隔离
消费者有自己的逻辑,在逻辑处理中有可能会出现 panic,我们需要消费者的 panic 限制在协程里,以避免协程崩溃影响主进程。
Go 有 recover 机制,可以让你捕获 panic 并且限制 panic 不在向上蔓延。代码如下:
go (func() {
defer func() {
if err := recover(); err != nil {
fmt.Println("捕获到 panic:", err)
return
}
}()
err := EventHandle()
if err != nil {
Logger.Error("event 处理监听失败", err)
}
})()
消费者协程保活
消费者业务逻辑在协程里,可能在一些场景(panic 或其他不可知情况)下意外退出,我们需要保证能够重新拉起消费者协程,从而保证整个事件逻辑的闭环。
在这里我们用管道实现一个心跳机制,消费之定时发送心跳到主进程,如果超过一段时间没有发送心跳主进程会认为消费之已经出现异常,会重新拉起一个协程消费者。
主进程监听心跳代码如下:
func monitorHeartbeat(heartbeat chan bool) {
// 设置心跳包的超时时间
timeoutDuration := 3 * time.Second
timer := time.NewTimer(timeoutDuration)
for {
select {
case <-heartbeat:
// 接收到心跳包,重置定时器
timer.Reset(timeoutDuration)
case <-timer.C:
// 超时,重新启动协程
fmt.Println("心跳超时,重新启动协程")
go startEvent(heartbeat)
timer.Reset(timeoutDuration)
}
}
}
协程发送心跳包代码如下:
func EventHandle(heartbeat chan<- bool) error {
for true {
heartbeat <- true
other code...
}
}
其他
在 event hadle 阶段,还需要考虑,并发锁、异常重试和重试失败后的日志记录等问题。
总结
到此整个事件系统的一些关键点就讲完了,如果仅仅是事件的监听和分发的开发工作可能很快就完成了。但是我们围绕着这个核心功能做了很多的额外工作,也正是这些工作才能保证我们整个方案的平稳运行。
有句话说的好功夫在诗外,那些让我们立于不败之地的恰恰那些看不见的"多做的"事情。
如果文章对你有帮助或者你有其他不通想法,欢迎评论交流。
